


Szybciej, taniej, potężniej: DeepSeek przedstawia nową wersję swojego modelu językowego
Chińska firma technologiczna DeepSeek przedstawiła ulepszoną wersję swojego dużego modelu językowego sztucznej inteligencji DeepSeek-V3-0324, zaledwie trzy miesiące po wydaniu pierwszej wersji V3 w grudniu 2024 roku.
Zaktualizowany model wyróżnia się zwiększoną wydajnością i rozszerzonymi możliwościami, w tym zdolnością do tworzenia wizualnie atrakcyjnych stron internetowych i wysokiej jakości raportów w języku chińskim.
DeepSeek-V3-0324 przyciąga uwagę swoimi obniżonymi wymaganiami dotyczącymi zasobów obliczeniowych do szkolenia, skróconym czasem treningu oraz bardziej przystępnymi cenami na API, zachowując przy tym wysoką wydajność w porównaniu z konkurentami, takimi jak GPT od OpenAI.
Jedną z kluczowych cech nowego modelu jest brak etapu “rozmyślań”, co pozwala mu na szybkie udzielanie odpowiedzi, bez zatrzymywania się na skomplikowanych zadaniach, w przeciwieństwie do poprzedniego modelu DeepSeek R1.
Rozmiar parametrów nowej wersji wynosi 685 miliardów, co czyni ją jednym z największych publicznie dostępnych modeli językowych na dziś.
DeepSeek-V3-0324 wykazał poprawę wyników w testach sztucznej inteligencji o 5,3-19,8% w porównaniu z poprzednią wersją, zbliżając się pod względem wydajności do takich liderów jak GPT-4.5 i Claude Sonnet 3.7.
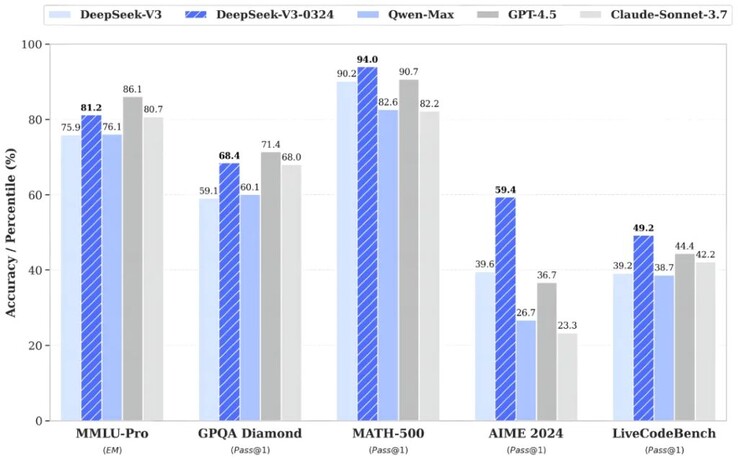
Dodatkowo, zaktualizowana wersja wykazała znaczący postęp w tworzeniu stron internetowych, a także w wyszukiwaniu, pisaniu i tłumaczeniu tekstów w języku chińskim.
Aby w pełni wykorzystać model DeepSeek-V3-0324, użytkownicy będą potrzebować co najmniej 700 GB wolnego miejsca na dysku oraz kilku procesorów graficznych Nvidia A100/H100. Jednak dostępne są także uproszczone wersje modelu, które mogą działać na jednym GPU, na przykład Nvidia 3090.